Order pattern looks irregular—so irregular that your first reaction is:
“This is intermittent demand; forecasting will be messy.”
And yes, sometimes it is.
But in many cases, it’s not “absolutely irregular.” There are patterns. The problem is that we often look for the wrong ones.
Let me walk through a case I’ve seen more than once—and why a standard forecasting approach can produce horrible accuracy, even when the demand is actually quite structured.
Pattern #1: Irregular timing, but a stable weekly “envelope”
At first glance, the orders arrive at inconsistent intervals. One week you get a hit, next week nothing, then two dips close to each other.

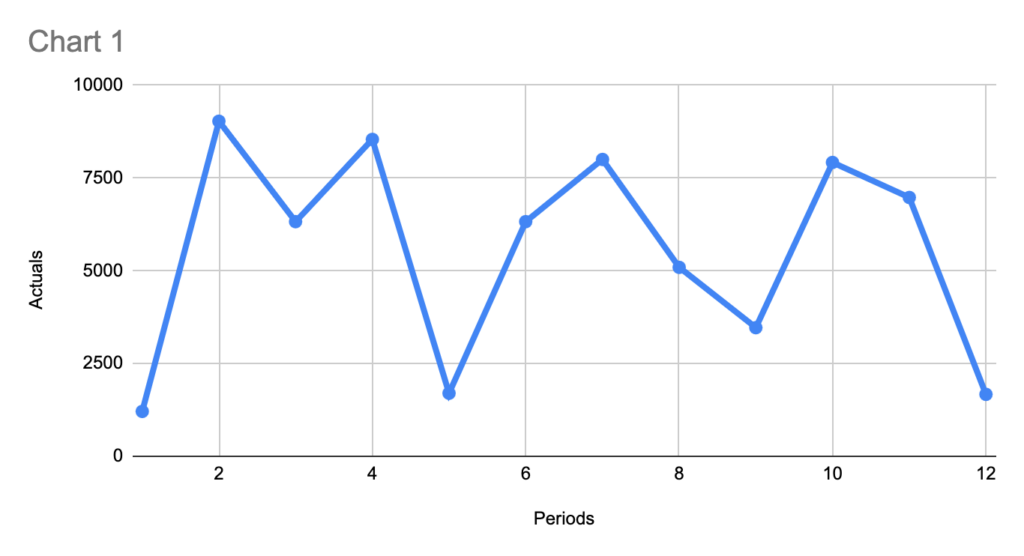
Still, when you zoom out, you often see an estimated volume of demand per quarter that is stable. Look at same data on Quarterly granularity:

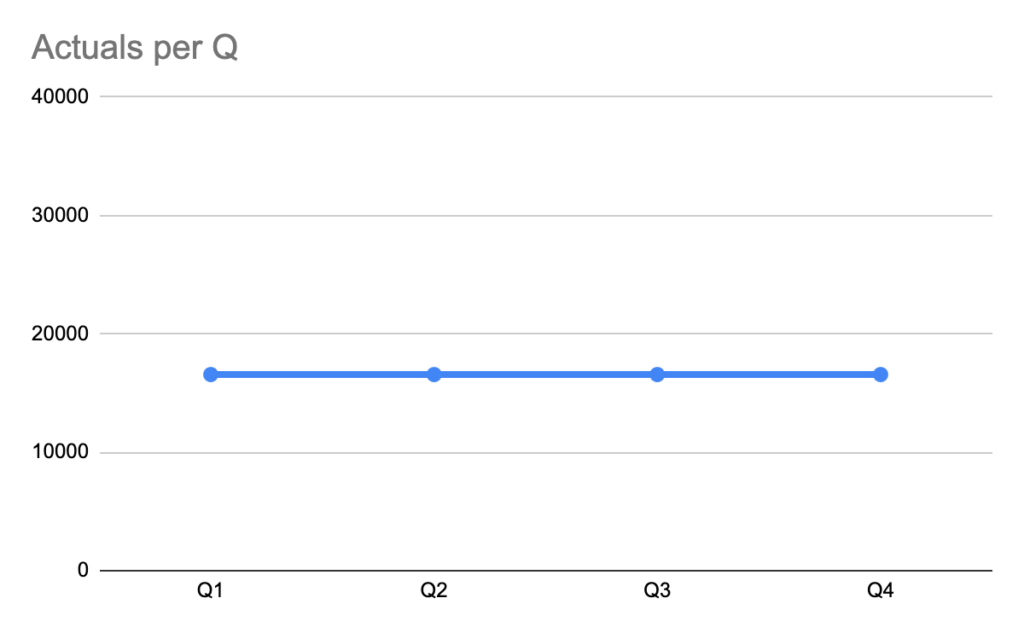
In other words:
Order timing is irregular
But average quarterly throughput is not crazyPattern – straight-forward. But only if you zoom out.
Pattern #2: Volumes repeat — because quantities are discrete (not continuous)
Some SKUs are ordered only in a specific base quantity (a “base unit”), always.
If the customer makes an order, it is always:
exactly the Base Unit, or
a clean multiple of itExample :

In such a case, making statistics on “number of kg” as if it were a smooth continuous variable often makes no sense. The demand is quantized.
So even if your weekly forecast is “close” in an average sense, it can still be operationally wrong because it predicts values that cannot happen in reality (e.g., 1433 kg when the only feasible outcomes are 792 or 1584 kg).
This is a classic planning trap:
Forecast looks mathematically reasonable
But it violates the ordering grammar of that SKU/customer combination
Result: big errors, low trust, bad downstream decisions (inventory, production, transport planning)Why does this happen?
Because the demand you observe is not purely consumption-driven—it’s consumption filtered through ordering constraints, such as:
pack size / layer / pallet multiples
minimum order quantities (MOQ)
full-truck or delivery-slot economics
internal customer ordering habits (“we always order 2 pallets”)
system constraints (ERP rounding, UoM conversions)The “real” consumption may be smoother, but your order history is a rounded and batched signal.
Can SAP IBP help? Yes, in concept—sometimes not in practice
A potential solution direction is using Time Series Properties in SAP IBP (feature engineering for time series):
In general, the concept is great: it encourages you to explicitly describe characteristics of the series and derive smarter features.
But here’s my observation from the field:
The limitation: it may not catch “base-unit multiple” demand
These discrete-multiple patterns are not just seasonality, trend, or noise. They’re more like a rule-based quantization of order quantities.
If the feature framework doesn’t explicitly detect and represent “order quantities come in multiples of X,” then:
the model can still average across outcomes
and it will keep producing “in-between” numbers that never occurPractical way to think about it (what usually works better)
If I had to summarize the right mental model:
Don’t forecast “kg” first. Forecast the ordering mechanism.
A robust approach is usually two-layer:
When will an order occur? (order event / probability)
If an order occurs, how many base units will it be? (1x, 2x, 3x…)Then convert back to kg if needed.
Even without building a complex ML stack, you can often improve results by introducing a simple constraint/post-processing step:
detect the base unit from history (e.g., most common divisor or most frequent quantity step)
forecast demand level
then snap/round the forecast to the nearest feasible multiple (with sensible business rules)This alone can drastically reduce “nonsense forecasts” and improve planner trust—even if your underlying model doesn’t change.
Final thought
“Irregular orders” is often a misleading label. Many series are irregular in timing, but highly regular in allowed quantities. If you ignore that discreteness, you can spend months tuning models and still get terrible accuracy—because the model is solving the wrong problem.